Extracting Data From PDFs Using AI: Claude 3, Donut, and Nougat


Parsing and extracting data from scanned PDFs and images like invoices is a difficult task. It involves complex actions like reading text and fully understanding the content of the document.
Most current methods use OCR (Optical Character Recognition) engines to read the text and then work on understanding the document using the text that the OCR provides.
However, relying on OCR has some drawbacks: 1) it's computationally expensive; 2) OCR models may not work well with all languages or document types; 3) errors made by OCR can affect the next steps of the process (source).
In this article, we are going to test three OCR-free AI models for document extraction needs: Claude 3, Donut, and Nougat. Specifically, we will write simple Python scripts to parse invoices, PDF tables, and receipts.
Claude 3 Haiku
Claude is a family of large language models developed by Anthropic.
Claude 3 models, the most advanced models released in March 2024, can analyze images. We are going to use this feature to parse scanned invoices into structured JSON format.
The family includes three AI models: Haiku, Sonnet, and Opus. They have different capabilities and costs.
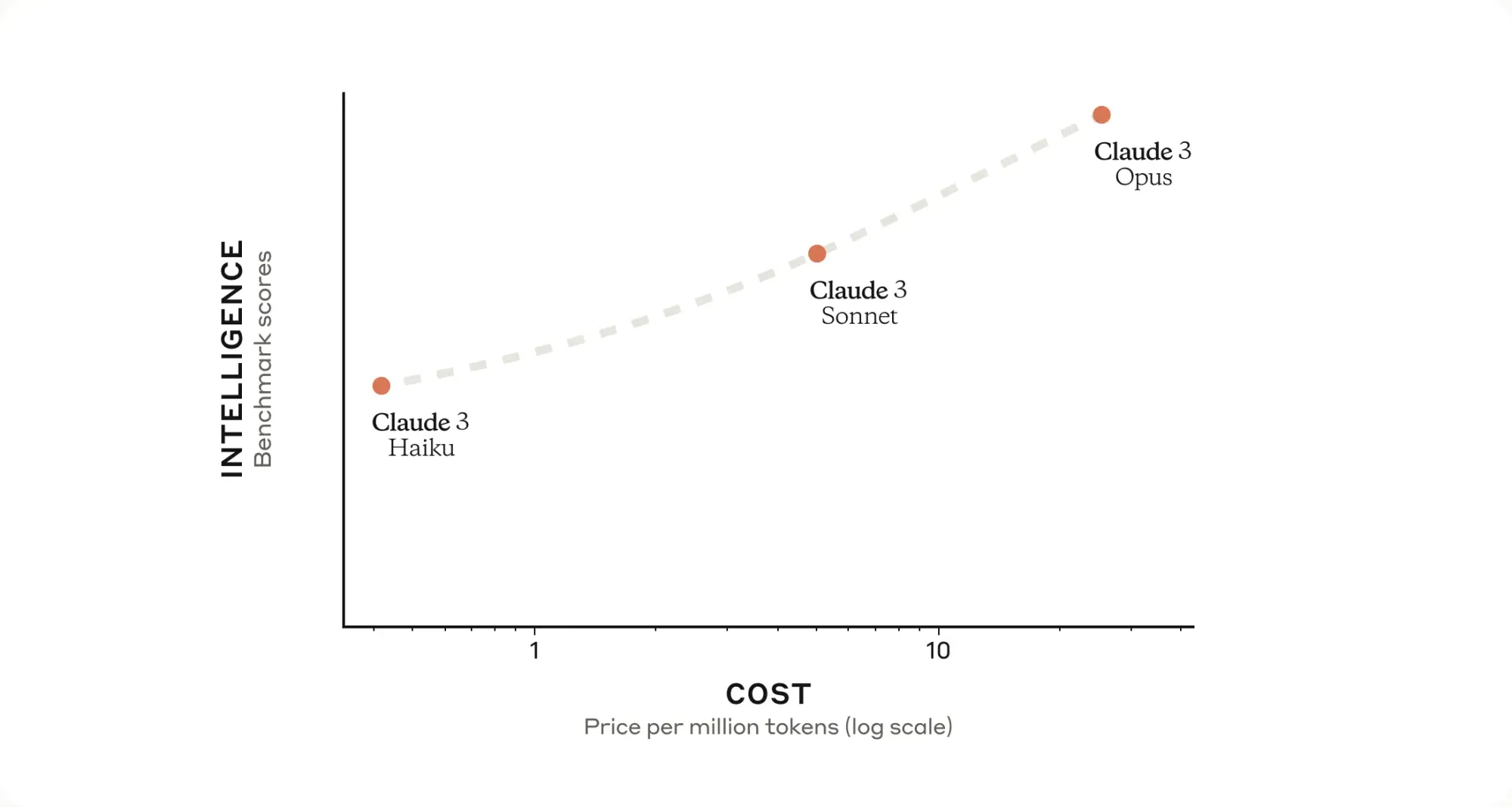
To parse scanned documents, the cheapest Haiku model is more than sufficient. For tasks like document classification, it's probably more advisable to choose the Sonnet model.
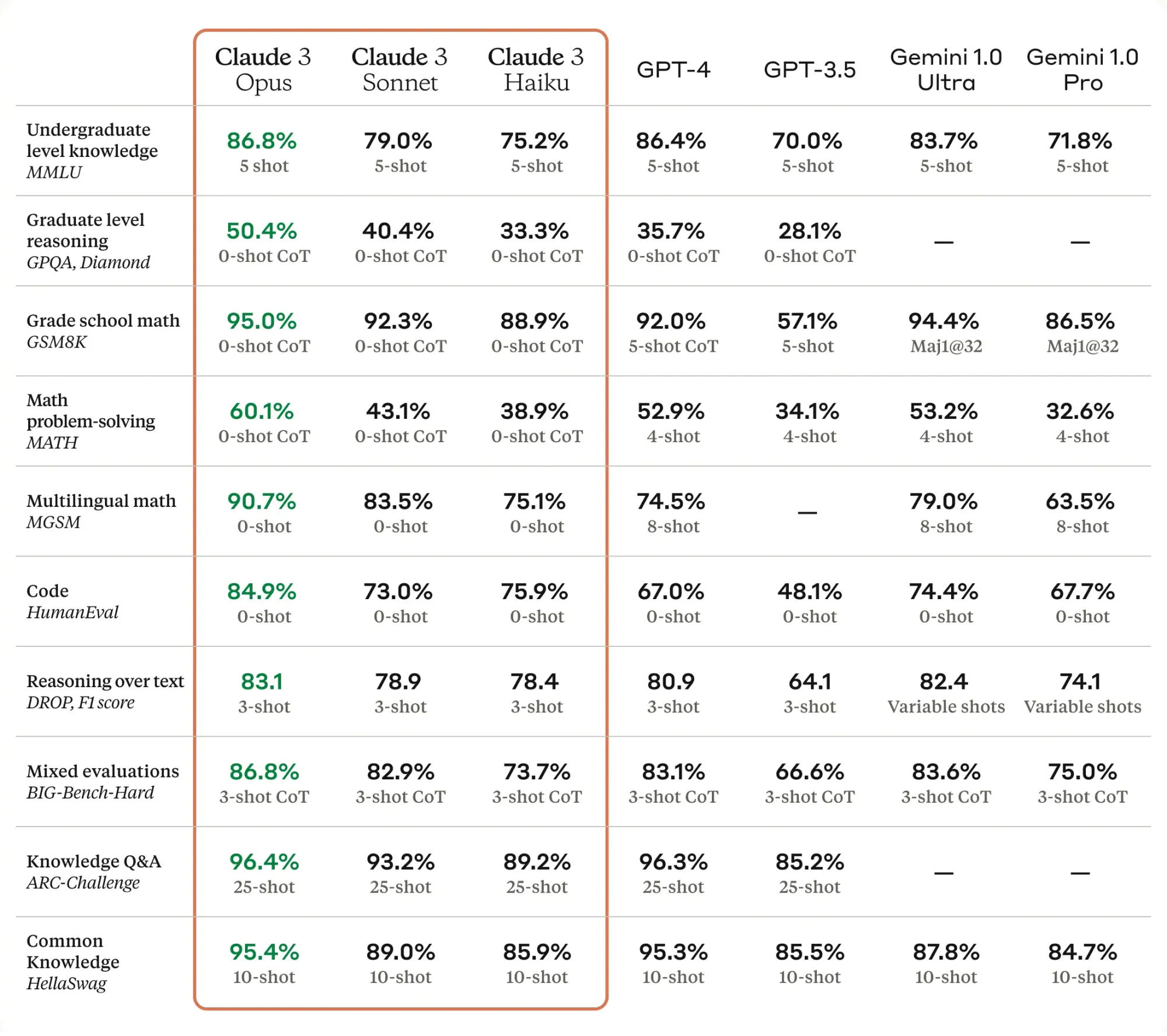
The Python code below is heavily inspired by the Open-DocLLM repository.
POST endpoint that accepts a binary file and an extraction schema (a list of fields that we are going to extract):
@app.post("/extractClaude")
async def process_image_with_claude(file: UploadFile = File(...), extraction_schema: str = Form(...)):
# Create a temporary file and save the uploaded file to it
temp_file = tempfile.NamedTemporaryFile(delete=False)
shutil.copyfileobj(file.file, temp_file)
file_path = temp_file.name
# Convert the file to base64
with open(file_path, "rb") as f:
base64_encoded_image = base64.b64encode(f.read()).decode()
# Create an instance of AnthropicsApiService
api_service = AnthropicsApiService(API_KEY_ANTROPIC)
# Prepare the prompt
prompt = f"###Invoice\\n{extraction_schema}"
# Build the messages
messages = [Message(role="user", content=prompt)]
# Set the model
model = "claude-3-haiku-20240307"
# Create an instance of AnthropicsApiRequest
api_request = AnthropicsApiRequest(
model=model,
max_tokens=2000,
messages=messages,
system="You are a server API that receives an image and returns a JSON object with the content of the invoice supplied"
)
# Send the data to the Anthropics service and get the response
response = api_service.send_image_message(api_request, base64_encoded_image)
# Return the response
return {"Content": json.loads(response)}
An extraction schema for invoice parsing can be defined as follows:
invoice_id: string
invoice_date: date
customer: object
name: string
address: string
phone: string
supplier: object
name: string
address: string
phone: string
items: array of objects
qty: number
description: string
unit_price: float
total: float
currency: string
subtotal: float
sales_tax: float
shipping_fee: float
total: float
currency: string
Preparing and making an API call:
def send_image_message(self, initial_request: AnthropicsApiRequest, base64_image: str) -> str:
final_response = None
request = initial_request
sb = []
messagesContent = [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64_image
}
},
]
messagesContent.append(
{
"type": "text",
"text": request.messages[0].content
}
)
while True:
start_time = time.time()
message = self.client.messages.create(
model=request.model,
max_tokens=request.max_tokens,
temperature=0,
system=request.system,
messages=[
{
"role": "user",
"content": messagesContent
}
]
)
response_time = time.time() - start_time
print(f"Response time: {response_time} seconds")
if hasattr(message, 'error') and message.error and message.error['type'] == "overloaded_error":
continue
if hasattr(message, 'error') and message.error:
raise Exception(
f"API request failed: {message.error['message']}")
final_response = message
content = remove_json_format(final_response.content[0].text)
if final_response.stop_reason != "end_turn":
content = remove_last_element(content)
sb.append(content)
if final_response.stop_reason == "end_turn":
break
return "".join(sb)
The data is extracted with amazing accuracy:
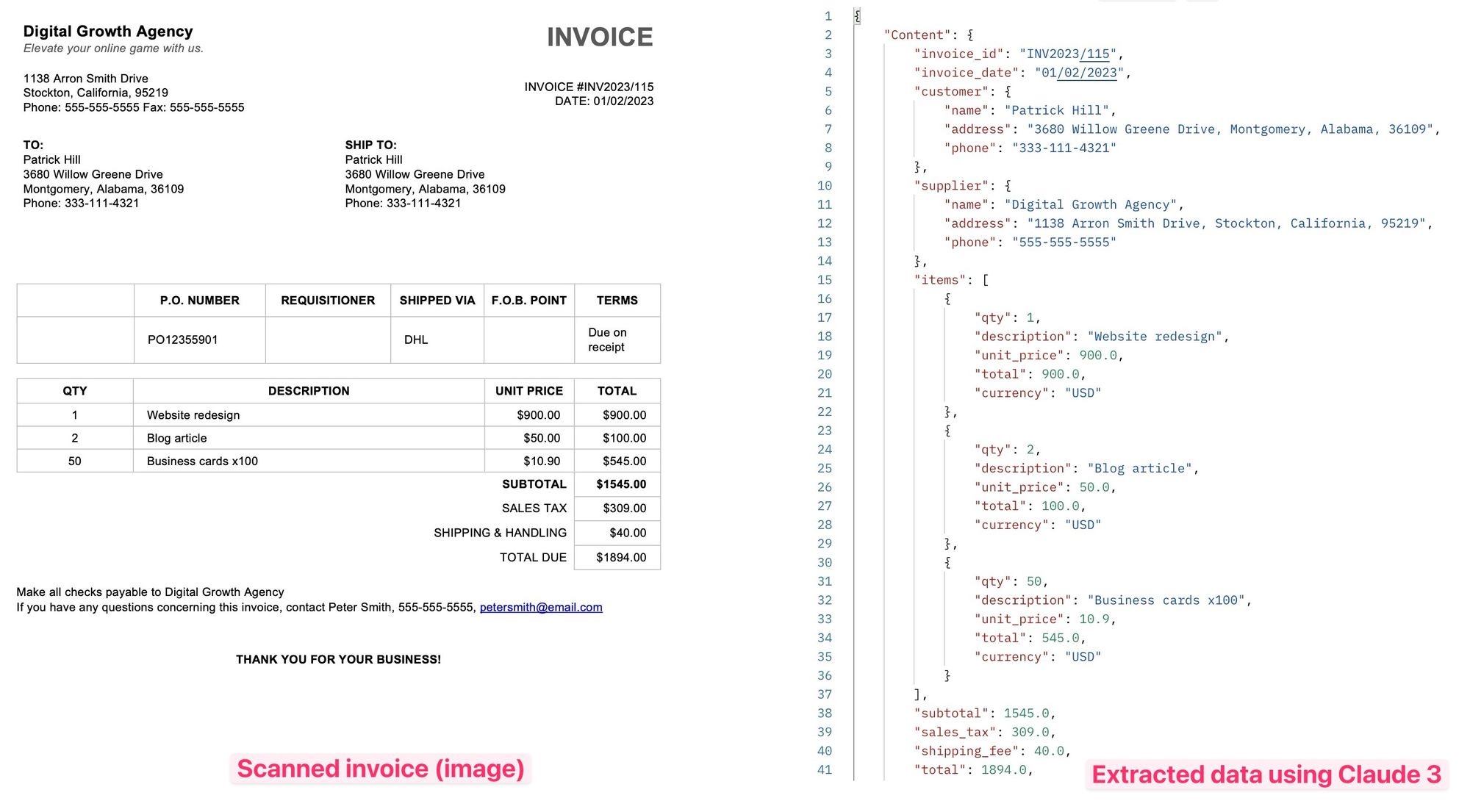
Donut
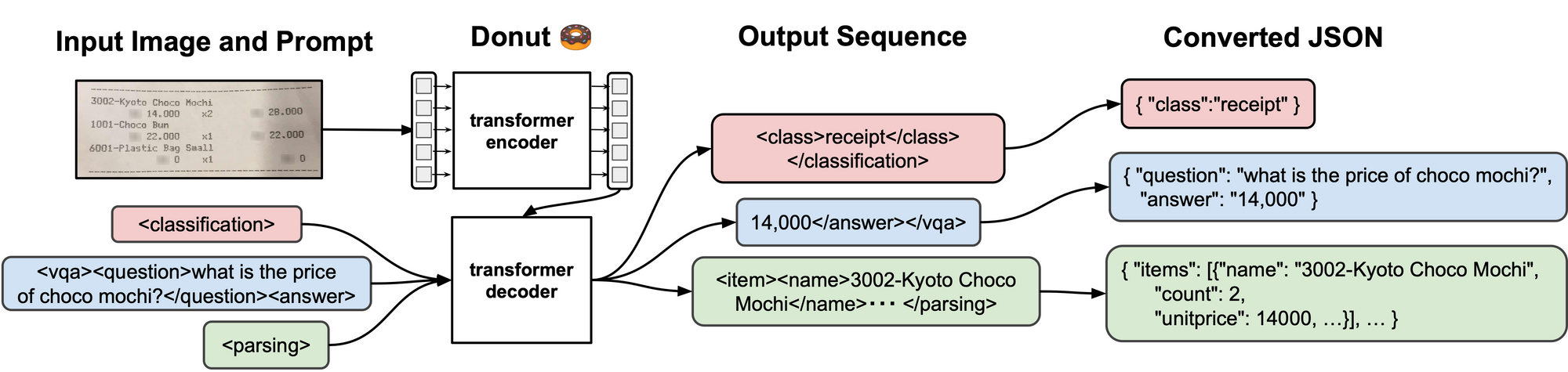
Donut (Document Understanding Transformer), developed by Clova AI, is an OCR-free approach to document understanding that uses an end-to-end Transformer model. Donut can be used for various visual document understanding tasks, such as visual document classification or information extraction (i.e., document parsing), visual question answering (DocVQA).
Installation: pip install donut-python .
Here's a Python script to convert a scanned receipt (a JPG file) into a structured JSON format using Donut. We use the model naver-clova-ix/donut-base-finetuned-cord-v2, which is trained on 800 receipts.
import re
from transformers import DonutProcessor, VisionEncoderDecoderModel
import torch
import json
from PIL import Image
processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-cord-v2")
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# load document image
img_path = './files/receipt_scan.jpg'
image = Image.open(img_path)
# prepare decoder inputs
task_prompt = "<s_cord-v2>"
decoder_input_ids = processor.tokenizer(task_prompt, add_special_tokens=False, return_tensors="pt").input_ids
pixel_values = processor(image, return_tensors="pt").pixel_values
outputs = model.generate(
pixel_values.to(device),
decoder_input_ids=decoder_input_ids.to(device),
max_length=model.decoder.config.max_position_embeddings,
pad_token_id=processor.tokenizer.pad_token_id,
eos_token_id=processor.tokenizer.eos_token_id,
use_cache=True,
bad_words_ids=[[processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
)
sequence = processor.batch_decode(outputs.sequences)[0]
sequence = sequence.replace(processor.tokenizer.eos_token, "").replace(processor.tokenizer.pad_token, "")
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
parsed_dict = processor.token2json(sequence)
# print the prettified dictionary
prettified_dict = json.dumps(parsed_dict, indent=4)
print(prettified_dict)

We can even try to parse an invoice using the same model:

As you can see, Donut's model extracts structured key-value pairs from scanned documents.
You can find more fine-tuned Donut AI models on Hugging Face. Some of them are trained to parse invoices, receipts, tickets, and are specialized for other tasks such as document classification.
References:
- GitHub: https://github.com/clovaai/donut
- Paper: https://arxiv.org/abs/2111.15664
- Fine-tuned models: https://huggingface.co/models?search=donut
- Demo: Donut trained on CORD dataset (receipts)
- Demo: Donut for Document Image Classification
- Demo: Donut for DocVQA
Nougat
Nougat (Neural Optical Understanding for Academic Documents) is an encoder/decoder transformer model developed by Meta. It can perform OCR and convert PDFs to MultiMarkdown (.mmd) format. It was specifically designed to parse academic documents, preserving text, math equations, formulas, and tables. It also simplifies the conversion of PDFs to LaTeX format.
Nougat is built using the Document Understanding Transformer (DONUT) architecture. You can train or fine-tune Nougat on your own dataset.
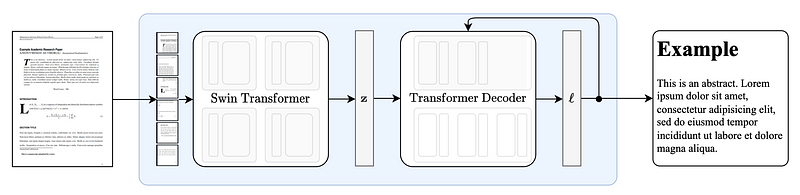
It functions as a command-line interface (CLI) program that you can install by executing the following command: pip install nougat-ocr .
Here's how you can use Nougat to OCR and convert a PDF file to Markdown:
nougat ./files/invoice.pdf -o ./out
It will generate a file invoice.mmd in your output directory.
You can also run Nougat from your Python code:
import os
cmd = 'nougat ./files/invoice.pdf -o ./out'
os.system(f"{cmd}")
To process multiple PDF files in a batch:
import os
cmd = "nougat -o ./out"
pdf_dir = './files'
for pdf in os.listdir(pdf_dir):
os.system(f"{cmd} pdf ./files/{pdf}")
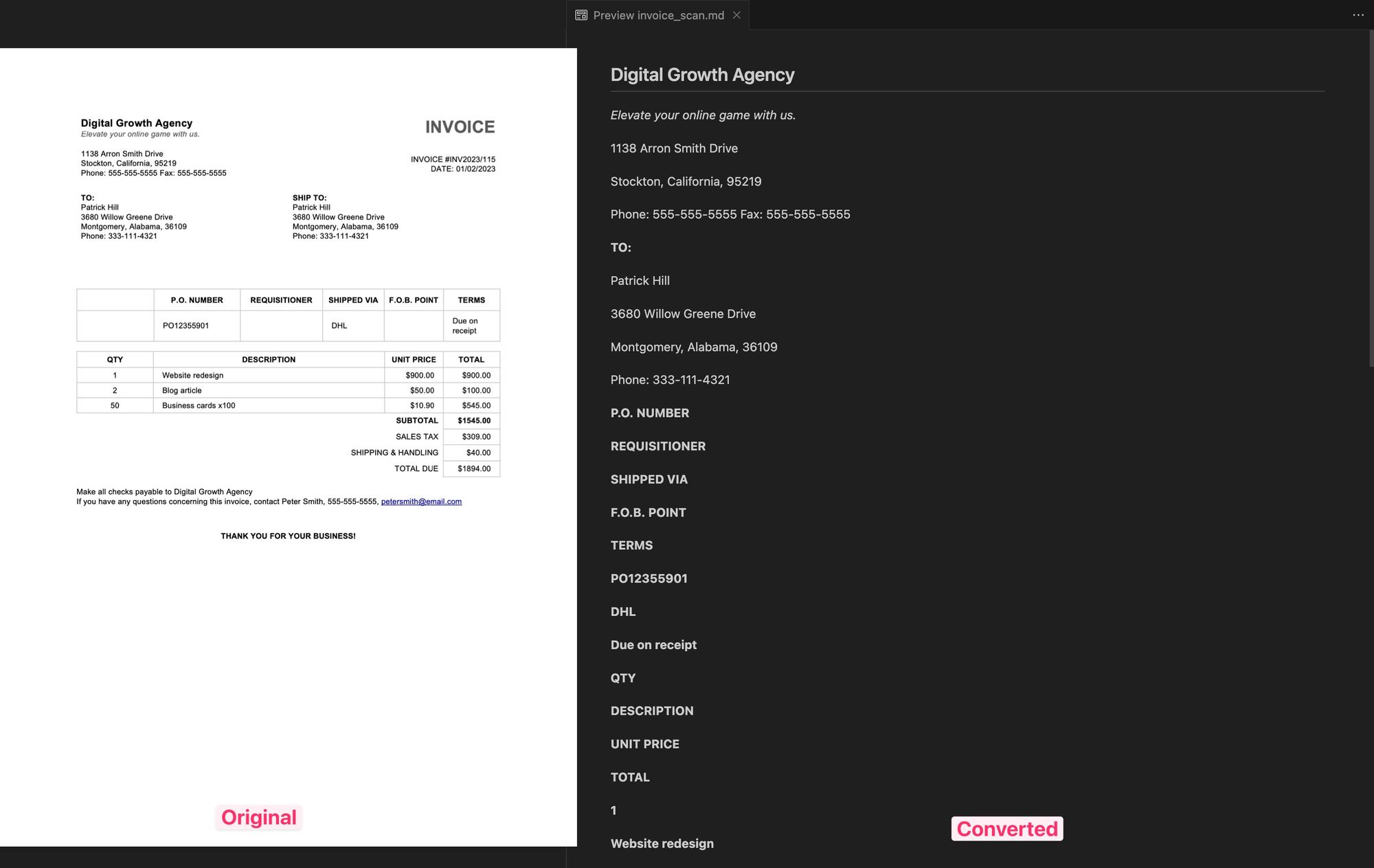
I've attempted to convert a sample invoice (an image that imitates a scanned document). The text was mostly extracted correctly, but almost without any formatting or tables in the output.
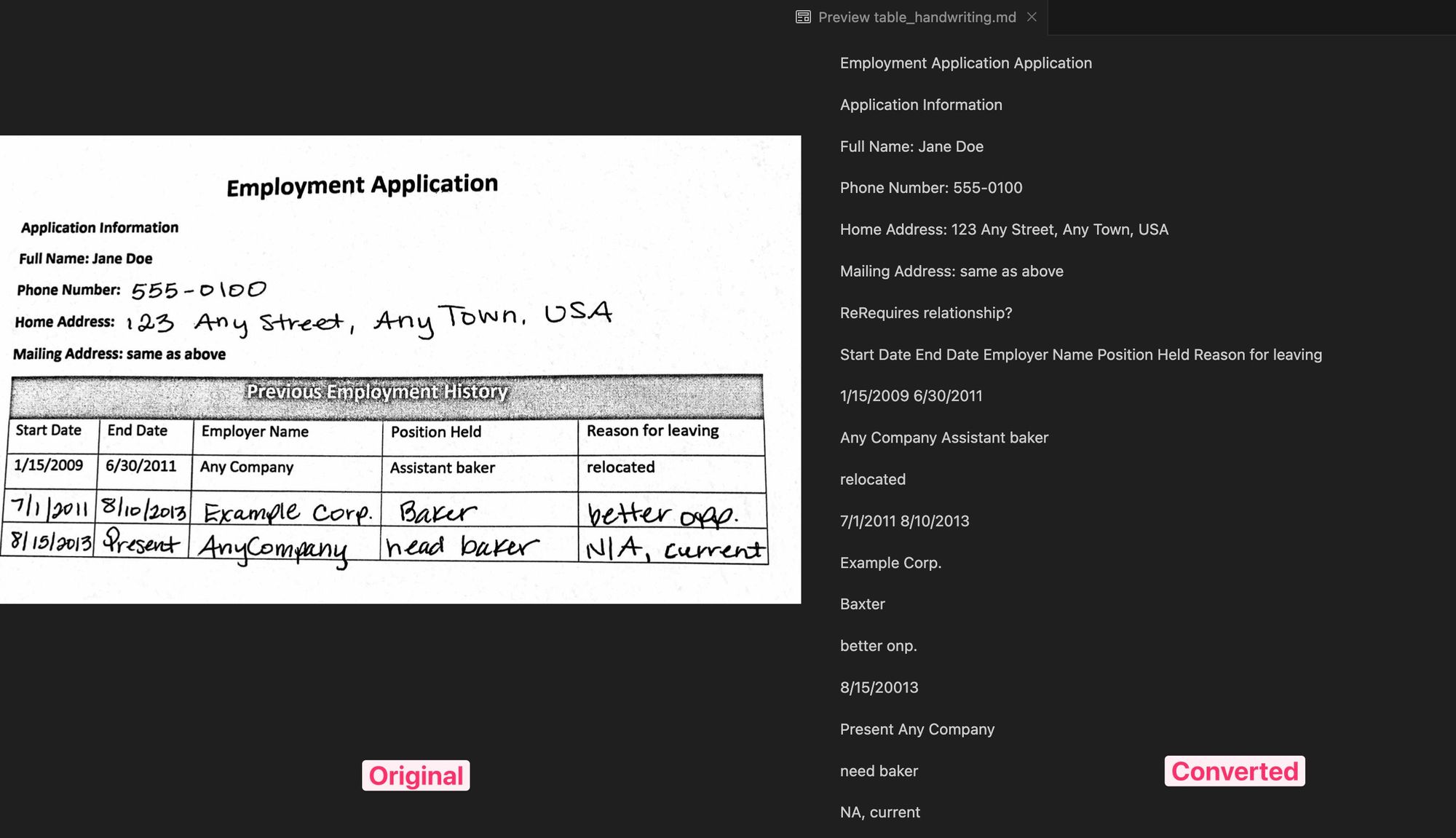
Then, I tried to parse a simple table with handwritten text. Again, the text (including the handwritten part) was extracted quite accurately, but without any formatting.
Meta's Nougat model is an excellent choice for scientific documents and articles with text paragraphs, formulas, and tables, but it performs much less effectively for invoices and other types of documents.
References:
- GitHub: https://github.com/facebookresearch/nougat
- Project page: https://facebookresearch.github.io/nougat/
- Paper: https://arxiv.org/abs/2308.13418
Conclusion
We have tested three AI models for OCR and PDF document extraction tasks: Claude 3, Donut, and Nougat. Each of them yielded satisfactory results and has its own advantages and disadvantages.
The Claude 3 model is likely the most flexible, allowing for quick creation of a custom extraction schema. However, it might not be the best choice for parsing large documents.